優化使用者體驗!透過推薦演算法來加速商業成長
回顧近期開發推薦演算法的心得。目前在服飾電商服務,就以服飾的推薦算法為場景舉例。本文談論的內容包含為何要開發推薦系統、推薦模型基本架構,以及在設計算法過程中要考慮的細節。
想像一個陽光普照春日下午,剛結束跟姐妹下午茶約會的你,在回家的路上偶然走進一間服飾店逛逛,也順便吹冷氣休息一下。看到店內有數百件各類型衣服,首先可能會大致瀏覽一下自己喜歡的類型、款式、顏色,也許拿幾件自己感興趣的洋裝出來比試一番,順便欣賞鏡中的自己。這時一旁的帥哥店員會簡單的跟你閒聊,同時根據你先前從衣架上拿下的商品的特徵來推薦當季的最新款、或更合你心意的洋裝款式。這位帥哥店員便是推薦系統了。
開發推薦系統的目的
推薦系統想解決的問題是,如何幫助使用者在資訊超載的情況下,高效率地獲得感興趣的商品資訊。以目前工作的電商網站為例,站上使用者能接觸的商品超過十萬檔,當這麼多商品一次擺在你面前,如何在短時間內找到自己適合的商品就會是個困擾使用者的問題。
站在公司角度,推薦系統產品是用來吸引使用者、提升用戶留存率與使用者黏性,進一步達到商業目標增長的目的。不同公司根據其商業模式,推薦系統的最佳化目標也不同。比方說,串流影音平台,注重的是使用者的觀看時長﹔新聞網站注重使用者的點擊率﹔電商公司更注重使用者的轉換率(Conversion Rate,CVR)。最終都是要達成公司的商業目標,增加公司收益。
從工程面看,推薦系統是利用使用者在站上過往的歷史紀錄⎡猜測⎦使用者可能會喜歡的內容。
推薦模型架構概述

完整的推薦模型由上圖的幾個抽象單元組成。
- 候選物品庫(candidate items):可用來推薦的所有站上商品。
- 召回層(recall layer):從巨量的候選品中利用規則、演算法、簡單的模型,先過濾出一群使用者可能有興趣的物品組成候選物品集。實作方式可以是商品的熱門度計算,例如商品的點擊率、加車率等。
- 排序層(sorting layer):前一層篩選出的物品,帶有的各種評價指標,進行細部重組、排序,得到將出現在推薦清單的先後次序。
- 推薦清單(recommendation list):最終輸出給使用者的推薦清單。
上圖架構是個簡單的示例。實務上根據需求,及算法的設計考量,每個算法間的模型架構、計算方法也可能有很大的差異。
根據商業目標決定推薦算法的開發方向吧
這次的應用場景是app 推播服務,有別於過往電商的app推播對所有用戶都推送一致內容,這次想要製作客製化推播內容來增加用戶的對服務的黏著度與轉換率。
換句話說,就是要開發一個個人化的商品推薦模型,讓每個不同的使用者都會得到一份符合自身偏好的商品推薦清單。而這份推薦清單至少要包含兩個面向:
- 挑選商品需滿足商品的多樣性、新鮮度、與即時性
- 貼近用戶偏好的推薦
多樣性、新鮮度、與即時性
一個及格的推薦模型,推薦結果大多要包含上面標題中的三個面向。也是在開發算法時首先要考慮的問題。
- 多樣性:代表推薦商品在類別上、風格上或其它商品特徵上,希望保持多樣性,讓使用者感覺豐富、不無聊。比如說,給看過許多件上衣的用戶,推薦可做搭配的短褲或其他熱門類別。但換個角度想,是否每個用戶都喜歡多樣化的推薦清單呢?也許該用戶只有購買上衣的需求,若同時推薦的品項、類別用戶完全沒興趣,就可能浪費了一次推薦系統可帶來效益的機會。
- 新鮮度:推薦最新上架商品為佳,或是一定比例包含有高點擊率的長春熱賣品呢?長春商品點擊率佳,容易滿足商業目標;但推薦新商品則有機會測試用戶當季偏好,進而創造下一個長春商品,並擴大推薦商品池。在不同考量下將影響到候選商品池的大小,候選商品池太小,隨後算出的推薦清單長度可能太短。另外,已經推薦過的商品要隔多久才能再次被推薦,這也是個考慮新鮮度的面向。
- 即時性:也許用戶兩週前看了很多洋裝、但最近兩天的進站開始逛起T-shirt,是不是代表用戶這次想買T-shirt呢?若希望能及時反應用戶喜好,就要考慮多久更新一次推薦清單,是每週更新,每日更新、還是每小時更新?還有一次計算多久的user log(用戶日誌)能夠洽當的對用戶當下需求做反應,一次計算越多的user log 對模型來說可信度較高,但也有可能對使用著最近期的行為反應不佳。但只使用短期的user log做計算則無法得到足夠資訊計算用戶的行為偏好。
實務上根據不同的商品性質與商業模式,對多樣性、新鮮度、即時度的考量也會不同。
由上面的論述我們能了解到,如何定義以及正確理解用戶上站的意圖十分重要。若要做到個人化推薦,則要下更多功夫針對每個用戶去理解他們的喜好。
如何貼近用戶偏好
就像上面服飾店帥哥店員根據你的喜好推薦衣服給你,個人化推薦,換句話說即是人貨媒合。從使用者過往瀏覽紀錄提取使用者資訊,計算使用者特徵(使用者偏好)、再搭配商品特徵,同時考慮應用場景,來計算每個使用者(user)對每件商品(item)的偏好程度。
這裡先說明什麼是商品特徵,商品特徵就像是使用者瀏覽陳列在架上的商品時,可能會在意的所有細節,包含:商品種類、價格、尺寸、顏色、衣長、裙長、風格….等等特徵。若你在擁有數萬檔商品的情況下,則會先請資料科學家對商品圖片訓練分類模型,讓模型自動化辨識全站商品的每個特徵,做商品自動化打標籤的工作。

使用者特徵(使用者偏好)則是根據使用者瀏覽過的商品們,讓標籤回流到使用者身上,組合出專屬該用戶的一組標籤資訊。某個用戶算出的偏好可能會是他喜歡白色長版T-shirt,以及紅色運動風休閒褲。
在實作使用者特徵時考慮的面向有:
- 考慮多長時間的user log:每個使用者上站的習慣、頻率不同,抓得時間太短,無法準確反映用戶偏好,抓得時間太長,也可能會過度強調過去的偏好而忽略了最近幾次用戶上站的需求。
- 每個特徵的重要性是否相同:舉例來說,比起商品顏色,用戶是不是更在意商品價格以及實際想買的是那個類別的商品?每個特徵的重要性可能是不同的。
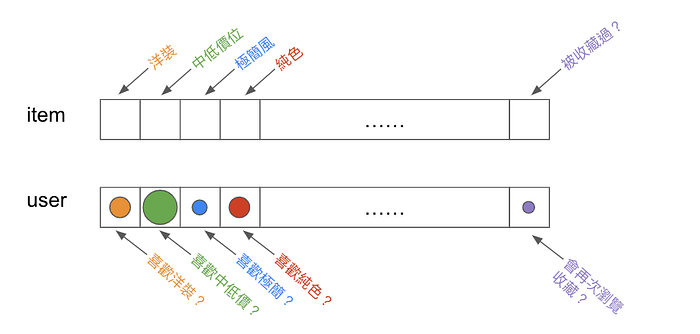
終於可以來說明如何計算用戶偏好拉。最簡單的偏好計算方式,可將使用者特徵與商品特徵作轉化為向量後做內積(inner product),利用內積來計算兩個向量的相近程度。該內積值,就可以當作是使用者對商品的偏好分數(perference score)。最終將上述每個使用者對所有商品的偏好分數計算出一個大小為(M, N)的矩陣,M是使用者個數,N是商品個數。我們將每個user Mi對 item Nj 的偏好分數 Sij 記錄於矩陣中。藉由排序偏好分數來得到某個使用者的最終推薦順序。
結語:
開發推薦算法常需要考量的各種面向,是本文想要紀錄的重點,上面都是在最近的開發經驗中收斂的心得。設計一個推薦系統需要很大部份的考量商業需求與應用場景,例如要針對新用戶的推薦清單、商品頁底下的推薦清單、app的推播,或是最終目的是想提升點擊率、訂單數…等等,每個應用場景與目的都需要客製化的設計算法架構,並沒有一體適用的解決方案。這也是推薦系統有挑戰性也具有魅力的地方。
Reference: 矽谷資深演算法大師: 帶你學深度學習推薦系統
若你喜歡這篇文章,多拍兩下吧🖐️🖐️